Three Formats Walk into a Lakehouse: Iceberg, Delta and Hudi in a Local Setup You Can Run on Your Laptop
I still remember building an entire bookkeeping system in FoxPro for my university coursework back in 2007. Planning every table structure upfront, carefully designing indexes because adding them later meant locking everything up for a reindex, managing backups manually, worrying about file corruption. Every schema change was a small crisis. Miss an index? Enjoy your full table scan. Need to add a column? Hope you like downtime.
Fast forward to 2025 and I'm querying files with SQL like they're actual database tables. Files sitting in object storage, pretending to be tables, with ACID transactions and time travel thrown in. The evolution from FoxPro to this is wild when you think about it.
Here's what happened: I kept reading about these lakehouse table formats - Iceberg, Delta Lake, Hudi - and the documentation was all features and concepts. ACID transactions, time travel, schema evolution... but I wanted to see what was actually happening on disk. What files get created? What does a "snapshot" physically look like?
So one evening I sat down, fired up Docker Compose with all three formats and started breaking things while watching what actually happened in storage. I wasn’t trying to benchmark performance or run fancy workloads, I just wanted to try the kind of basic operations every data engineer does daily: create a table, ingest some data, check the metadata, play with partitioning, alter the schema, drop a column, roll back a change.
Feel free to skip the article and jump straight to the repo.
The Setup: Your Lakehouse in a Box
I have this philosophy about technology: if I can't try it locally or in a free tier first, I usually pass. I want to understand what something actually does before committing to it. The good news is that all three lakehouse formats are open source and with Docker we can run the entire ecosystem on a laptop.
Here's what I threw together:
- PySpark notebook container - because let's be honest, I wasn't about to learn Flink or Trino just for this experiment
- MinIO for S3-compatible storage - for actually seeing what files are being created, deleted and modified in real-time
- Two months of NYC taxi data from NYC TLC - May and June as my test subjects
- Three notebooks, one per format, covering basics like table creation, snapshots and schema evolution.
Apache Iceberg - The One That Creates a Million JSON Files
To get Iceberg running you need three things:
- A compute engine - I used Spark 3.5 for all three formats.
- A catalog - This is basically a registry that keeps track of where your tables live and which snapshot is current. I went with HadoopCatalog (creatively named it
lake) which stores metadata right alongside the data in MinIO. In production you'd probably use Hive Metastore, AWS Glue or even a proper database like PostgreSQL. - Storage - Where everything actually lives. For this setup I pointed it to
s3a://my-bucket/iceberg-lakehousein MinIO. You can use MinIO, real S3, Azure Blob or even your local filesystem - it all works the same way.
Once you have these three pieces configured in Spark, you're ready to create tables and watch the metadata explosion begin.
I used the pyspark-notebook Docker image, which comes with Spark already configured, no need to mess with setting up a cluster or dealing with master/worker configurations.
If you follow README in my repo and run docker-compose up, everything should be up and running in a few minutes. You’ll see the two taxi Parquet files loaded into MinIO at localhost:9001 and a Jupyter notebook available at localhost:8888.
I tested this setup a bunch of times, but you know how it goes with Docker: what works on my machine might explode on yours. If something breaks, drop a comment and I'll fix it. The most common issue is probably port conflicts if you already have something running on 8888 or 9001.
After connecting Spark Iceberg and MinIO (and downloading what felt like half the internet in JARs) I created my first table:
CREATE TABLE IF NOT EXISTS nyc.taxis
USING iceberg
AS
SELECT * FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-05.parquet`
UNION ALL
SELECT * FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet`I immediately checked MinIO and... wow. Spark didn't just copy my Parquet files, it created an entire metadata universe:
The data/ folder had my actual data, rewritten as new Parquet files, but the interesting stuff was in metadata/:
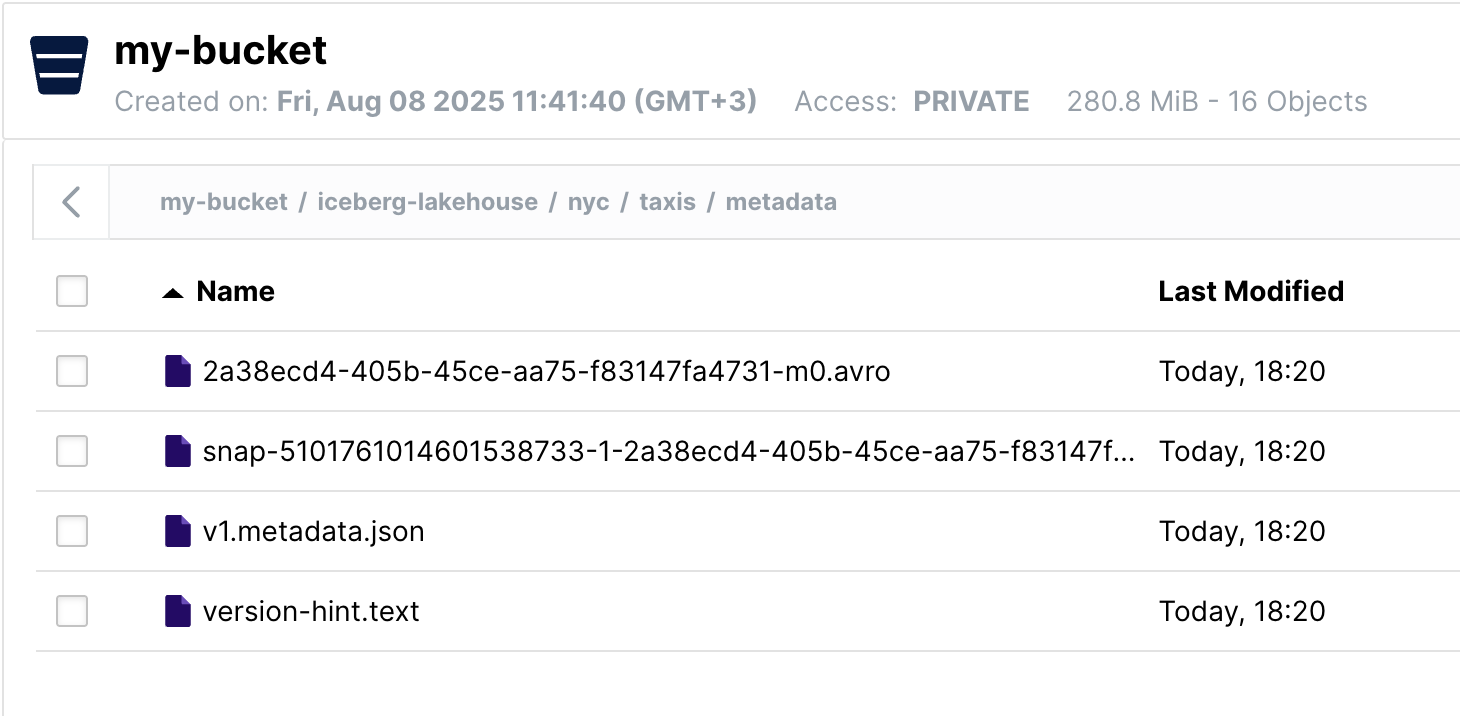
v1.metadata.json- the current table state with schema, snapshots and partition infosnap-<long-number>.avro- manifest lists pointing to actual data files- Various
.avromanifest files with statistics for query optimization
If you're curious about how all this fits together, the Iceberg table format documentation has a detailed breakdown of the metadata structure.
Every change creates a new snapshot. Let me show you by simulating another batch:
-- Add 10% of June data again (simulating a batch)
INSERT INTO nyc.taxis
SELECT * FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet`
WHERE rand() < 0.10;Then I checked the history:
SELECT * FROM nyc.taxis.history ORDER BY made_current_at DESC;
I got two snapshots: the original with 891K rows and the new one with 934K. The cool part? I can query both:
-- Original snapshot
SELECT count(*) FROM nyc.taxis VERSION AS OF 5101761014601538733;
-- Current snapshot
SELECT count(*) FROM nyc.taxis VERSION AS OF 3351842963272058702;
Time travel works. But what if I want to undo that insert? Simple rollback:
CALL lake.system.rollback_to_snapshot('nyc.taxis', 1295814594149623800)The data files from the second batch were still there, but v3.metadata.json now pointed back to the original snapshot. No data was deleted or copied, just metadata pointers changed. Let's check:
spark.sql("""
SELECT * FROM nyc.taxis.history ORDER BY made_current_at DESC;
""").show(truncate=False)
spark.sql("""
SELECT count(*) FROM nyc.taxis ;
""").show(truncate=False)
Looking at MinIO's metadata folder tells the whole story. I now have three versions of metadata.json (v1 from creation, v2 after the insert, v3 after rollback), each one a complete snapshot of the table state at that moment. The manifest files tell an interesting story too: that 2a38ecd4...m0.avro from 18:20 contains pointers to my original data files, while 3e4bb66c...m0.avro from 18:36 has the additional data from my insert. Both manifest files still exist because Iceberg never deletes anything immediately, it just changes which ones are "active" based on the current metadata version. The version-hint.text file now shows "3" - a simple counter helping readers find the latest metadata without scanning the whole directory. The data files from my insert are sitting in the data folder, orphaned but not deleted.
Iceberg metadata after insert and rollback
Let's try schema evolution:
ALTER TABLE nyc.taxis ADD COLUMN fare_bucket STRING AFTER total_amount;
UPDATE nyc.taxis
SET fare_bucket = CASE
WHEN total_amount < 10 THEN 'low'
WHEN total_amount < 30 THEN 'mid'
ELSE 'high'
END
WHERE total_amount IS NOT NULL;The UPDATE created a completely new set of data files (created at 19:03 in my video below). Old Parquet files didn't have the fare_bucket column, new ones did. Iceberg tracks which files have which schema version and no rewriting of old data is needed. Also we got v4.metadata.jsonand v5.metadata.json for ALTER TABLE and UPDATE.
Later, I found out you can also evolve the schema directly during writes, no ALTER TABLE needed. If you enable the 'write.spark.accept-any-schema' = true table property and set .option("mergeSchema", "true"), Iceberg will pick up new columns automatically. I dropped fare_bucket, added a new column (tip_rate_pct) directly in the DataFrame and appended the data. Iceberg updated the schema behind the scenes, added a new metadata version and moved on with its life. Old files stayed untouched, new files had the new column and the table just kept working.
from pyspark.sql.functions import col, when, lit, udf, round as sround
spark.sql("ALTER TABLE lake.nyc.taxis DROP COLUMN fare_bucket")
spark.sql("""ALTER TABLE lake.nyc.taxis SET TBLPROPERTIES (
'write.spark.accept-any-schema'='true'
)
""")
# Load the raw parquet file
df = spark.read.parquet("s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet")
# Compute tip_rate_pct as a percentage of the total fare
df_with_tip = (
df.withColumn(
"tip_rate_pct",
when(col("total_amount").isNull(), lit(None).cast("double"))
.when(col("total_amount") <= 0, lit(None).cast("double"))
.otherwise(sround(col("tip_amount") / col("total_amount") * 100.0, 2))
)
)
(df_with_tip.writeTo("lake.nyc.taxis")
.option("mergeSchema", "true") # Enables schema evolution on write
.append())
spark.sql("DESCRIBE TABLE lake.nyc.taxis;").show(30)Now for the real party trick - partition evolution. Most systems force you to rewrite everything when you change partitioning. Iceberg doesn't. (Yeah, this article is already huge and we're only one format in. It gets worse, I mean better, from here.)
-- Add day-based partitioning
ALTER TABLE nyc.taxis ADD PARTITION FIELD days(tpep_pickup_datetime);
-- Check the partitions
spark.sql("SELECT partition, record_count, file_count, last_updated_snapshot_id FROM nyc.taxis.partitions").show(truncate=False)

The result showed my existing data still sat in {NULL} partition (unpartitioned), while any new data I inserted would be partitioned by day. Old data stayed put, new data got organized. But what if I actually wanted to reorganize my existing data into those partitions? Iceberg has a procedure for that:
CALL lake.system.rewrite_data_files(
table => 'nyc.taxis',
strategy => 'binpack',
options => map(
'min-input-files','1',
'target-file-size-bytes','134217728',
'partial-progress.enabled','true'
)
)This kicked off a rewrite of all my data files. In MinIO, new partition folders appeared, files were reorganized and the metadata updated.
spark.sql("SELECT partition, record_count, file_count, last_updated_snapshot_id FROM nyc.taxis.partitions").show(truncate=False)
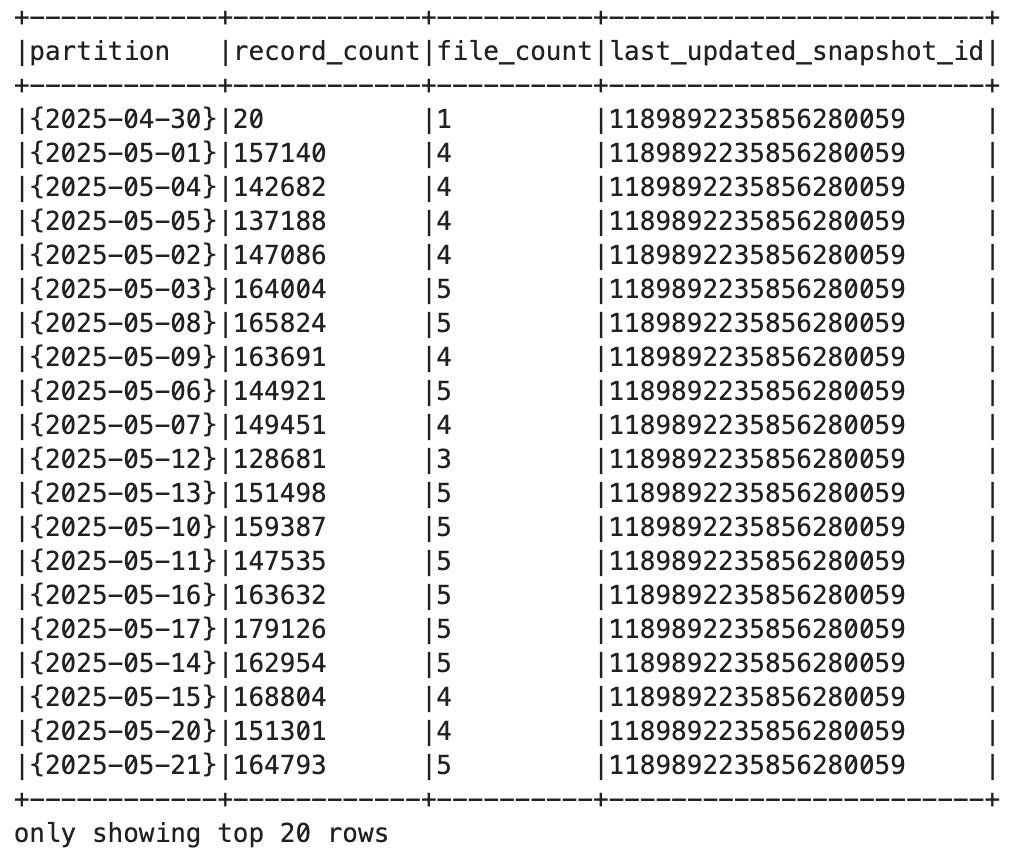
After it finished I had actual day-based partitions instead of that sad {NULL}. The history shows this as a regular commit:
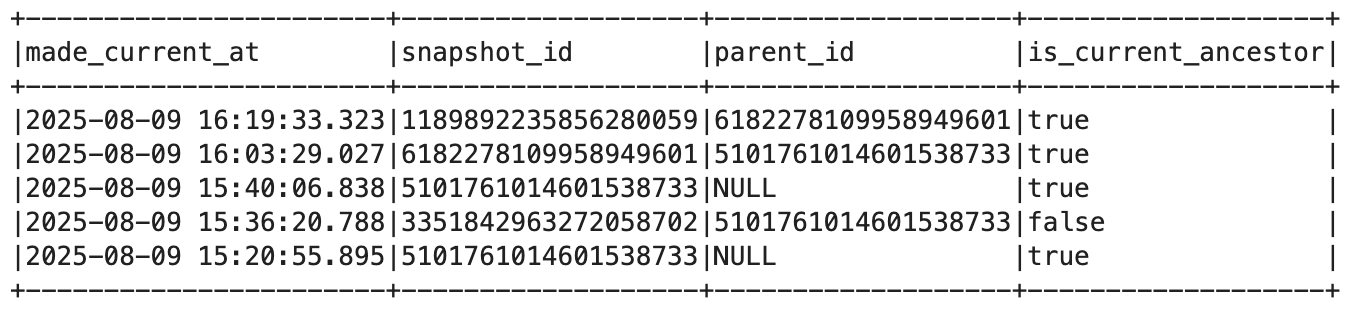
Four snapshots now: original creation, insert, schema evolution and this rewrite. Each one preserved and queryable. Even after partitioning and rewriting, I could roll back to the first snapshot:
CALL lake.system.rollback_to_snapshot('nyc.taxis', {snapshot_id_1})Checking partitions again - back to {NULL}.

The table had amnesia about ever being partitioned. All those carefully organized partition folders in MinIO? Still there, just orphaned. The original unpartitioned files? Iceberg found them again through the old metadata.
Looking at MinIO after all these experiments, the metadata folder had dozens of files now: multiple versions of metadata.json, manifest files for each operation, and snapshot files tracking everything. The data folder had original files, repartitioned files, files with new columns, all sitting there. Iceberg knows which ones are active, but from a storage perspective, you're accumulating a lot of orphaned data.
I could keep going - Iceberg has branching, tagging, hidden partitioning and probably a dozen other features I haven't touched. But this article is already approaching novel length, and we still have two more formats to explore. If you're curious about what else Iceberg can do, grab the notebook from my repo and experiment yourself. Breaking things is the best way to learn.
Time for Delta Lake.
Delta Lake - The Databricks Baby
To get Delta working I used the same setup as before: Spark as the engine, MinIO as the storage and that’s it. No catalog needed. Delta relies entirely on its _delta_log folder to track state.
I created the table from the same May and June taxi files:
CREATE TABLE IF NOT EXISTS nyc.taxis_delta
USING delta
LOCATION 's3a://my-bucket/delta-lakehouse/nyc/taxis'
AS
SELECT * FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-05.parquet`
UNION ALL
SELECT * FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet`MinIO showed my Parquet files as usual, plus a _delta_log folder. Inside are JSON files like 000000.json, 000001.json, etc. Each file is a commit - Delta logs every table change in append-only fashion. That’s how Delta enables versioning.
Checking the history shows every operation:
DESCRIBE HISTORY nyc.taxis_delta;
I ran another ingest and after that I could query any past version by specifying its number: 8914805 rows were after the initial ingest and 9346408 were after the second:
-- Count rows after initial load
SELECT COUNT(*) FROM delta.`s3a://my-bucket/delta-lakehouse/nyc/taxis` VERSION AS OF 0;
-- Count after an insert
SELECT COUNT(*) FROM delta.`s3a://my-bucket/delta-lakehouse/nyc/taxis` VERSION AS OF 1;

Under the hood Delta reads the commit log, finds out which files were active at that version and builds the table state from that. Nothing is physically deleted, everything is just metadata.
Rolling back is basically a metadata pointer change:
RESTORE TABLE nyc.taxis_delta TO VERSION AS OF 0;The table state pointed back to version 0, while the intermediate versions remained in the log.
Delta also has something the others don’t: Change Data Feed (CDF). It’s a built-in mechanism to track row-level changes between versions - not just which files were added, but what actually changed inside them. To enable it:
ALTER TABLE nyc.taxis_delta SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Once enabled, every commit logs detailed change events. I ran a small batch insert for June 15th, set some tips to zero and deleted short trips:
-- Insert some June 15th data
INSERT INTO nyc.taxis_delta
SELECT * FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet`
WHERE date(tpep_pickup_datetime) = '2025-06-15' AND rand() < 0.02;
-- Update tips to zero for that day
UPDATE nyc.taxis_delta
SET tip_amount = 0.0
WHERE date(tpep_pickup_datetime) = '2025-06-15' AND VendorID IN (1,2);
-- Delete very short trips
DELETE FROM nyc.taxis_delta
WHERE date(tpep_pickup_datetime) = '2025-06-15' AND trip_distance < 0.1;Then I queried the changes like this:
cdf = spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", 3) \
.option("endingVersion", 6) \
.table("nyc.taxis_delta")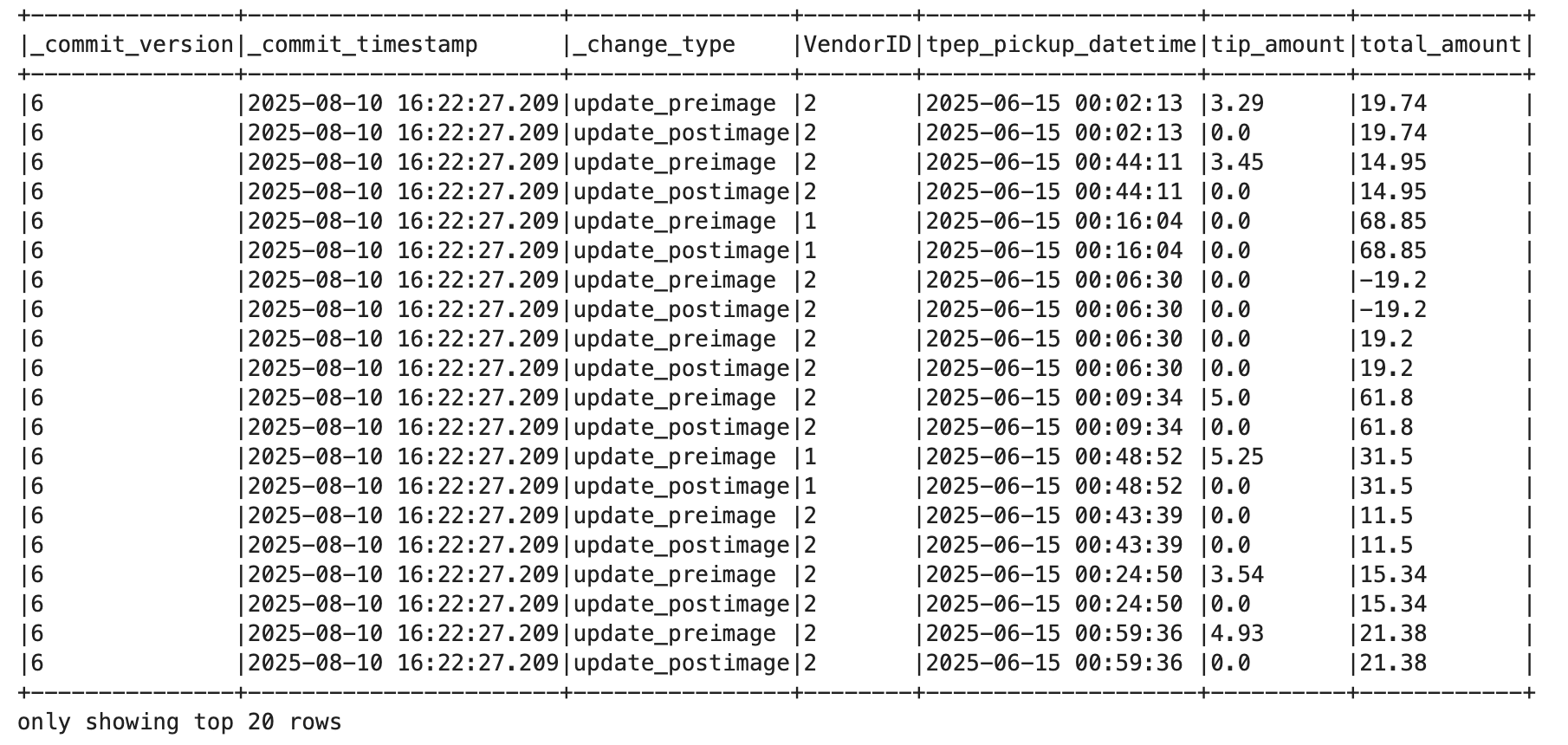
The result included _change_type fields like insert, update_preimage, update_postimage and delete. It also showed which version and timestamp each row came from.
I tried adding a column too:
ALTER TABLE nyc.taxis_delta ADD COLUMNS (fare_bucket STRING);
UPDATE nyc.taxis_delta
SET fare_bucket = CASE
WHEN total_amount < 10 THEN 'low'
WHEN total_amount < 30 THEN 'mid'
ELSE 'high'
END
WHERE total_amount IS NOT NULL;That almost worked until Delta ran out of memory trying to track all changes with CDF still enabled. I had to disable it to finish the update. Schema evolution is supported, but CDF makes it heavier than expected when you touch a large portion of the table.
I also wanted to try adding a new column (tip_rate_pct) without using ALTER TABLE, just to see if Delta could handle it during write. It can but only after a bit of setup. Since I had already added fare_bucket earlier, I needed to drop it first, but Delta refused until I enabled column mapping ('name' mode) and upgraded the table protocol to support column-level operations. After that I calculated tip_rate_pct directly in the DataFrame and appended it using .option("mergeSchema", "true"). Delta accepted the new column, evolved the schema and added a new version.
from pyspark.sql.functions import col, when, lit, round as sround
spark.sql("""ALTER TABLE nyc.taxis_delta SET TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5'
);""")
spark.sql("ALTER TABLE nyc.taxis_delta DROP COLUMN fare_bucket")
# Load June data again
df = spark.read.parquet("s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet")
# Compute the new column
df_with_tip = (
df.withColumn(
"tip_rate_pct",
when(col("total_amount").isNull(), lit(None).cast("double"))
.when(col("total_amount") <= 0, lit(None).cast("double"))
.otherwise(sround(col("tip_amount") / col("total_amount") * 100.0, 2))
)
)
# Append with schema evolution
(df_with_tip.write
.format("delta")
.option("mergeSchema", "true")
.mode("append")
.save("s3a://my-bucket/delta-lakehouse/nyc/taxis"))
spark.sql("DESCRIBE TABLE nyc.taxis_delta;").show(30)
Delta also locks in partitioning at creation. There’s no way to evolve it later like with Iceberg.
Looking at MinIO after all this, _delta_log/ had my commit history as JSON files and _change_data/ showed up after enabling CDF. The data folder had original files, new insert files and rewritten Parquet files from the update. Delta never rewrites files in place - it just creates more of them the same as Iceberg.
So in my flow, Delta worked mostly fine. Setup was simple, rollback and time travel were smooth and Change Data Feed was impressive once I understood how to use it. But the CDF memory hit during large updates is definitely something to watch out for.
You can try the same notebook here: delta.ipynb
Apache Hudi - The One That Tested My Patience
Setting up Hudi wasn’t smooth. While Iceberg and Delta mostly worked out of the box, Hudi felt like a test of patience. It required a specific Spark bundle (hudi-spark3.5-bundle_2.12:1.0.2), KryoSerializer (or else everything crashes with mysterious errors) and bumped memory configs for both driver and executor. Even basic inserts would sometimes fail with OutOfMemoryErrors unless I bumped the configs. And just because it worked once didn’t mean it would work again five minutes later. I restarted the Jupyter container more times than I’d like to admit.
Once it settled down, I created a Copy-on-Write (COW) table. In COW updates write new Parquet files and commit a new version that replaces the old files, so reads are simple and fully compacted while writes pay the cost. Hudi expects a bit more structure from your schema. You need:
uuid: a primary key (required for updates/merge logic)ts: a timestamp column used for deduplicationpartitionpath: an explicit partitioning column
Here’s what my table looked like:
CREATE TABLE IF NOT EXISTS nyc.taxis_hudi (
-- all the taxi columns...
ts TIMESTAMP,
uuid STRING,
partitionpath STRING
)
USING hudi
PARTITIONED BY (partitionpath)
TBLPROPERTIES (
type = 'cow',
primaryKey = 'uuid',
preCombineField = 'ts'
)After inserting data from my May taxi file I checked MinIO:
The structure was completely different from Iceberg and Delta:
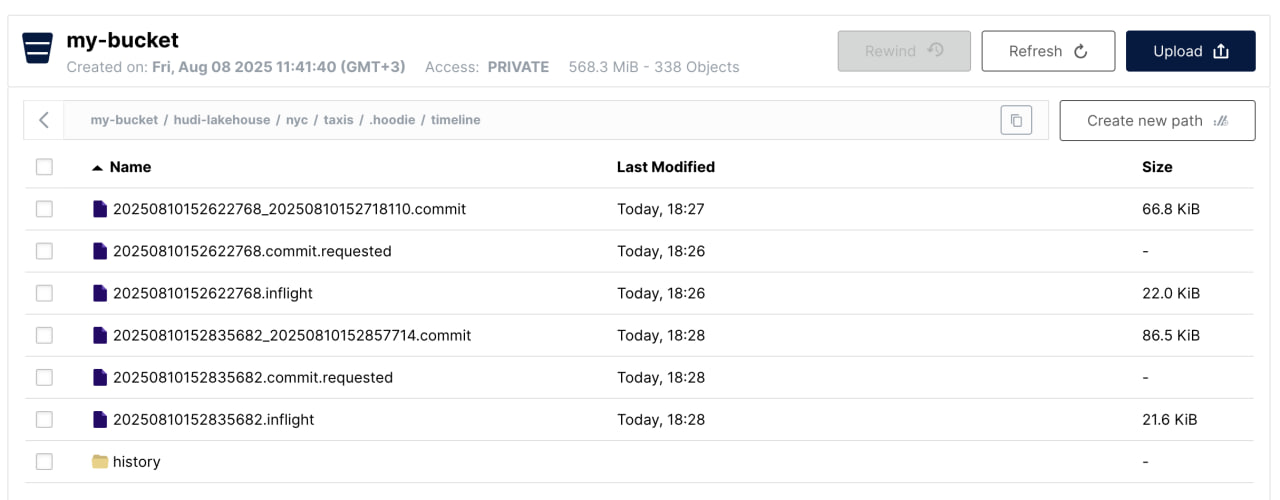
.hoodiefolder with metadata about commits and propertiestimelinefolder tracking every operation. Each operation creates three files:.requestedwhen it starts,.inflightduring execution and.commitwhen done. If something crashes, you'll see orphaned.inflightfiles everywhere.- Actual data stored in partition folders with long UUID-named Parquet files. Hudi created folders for each PULocationID value.
- No clean separation between data and metadata like in Iceberg
Then I ingested a random 10% of June data and ran the show_commits command:
spark.sql("""
INSERT INTO nyc.taxis_hudi
SELECT
*,
tpep_pickup_datetime AS ts,
uuid() AS uuid,
CAST(PULocationID AS STRING) AS partitionpath
FROM parquet.`s3a://my-bucket/raw-files/yellow_tripdata_2025-06.parquet` WHERE rand() < 0.10;
""")
spark.sql("CALL show_commits(table => 'nyc.taxis_hudi')").show(truncate=False)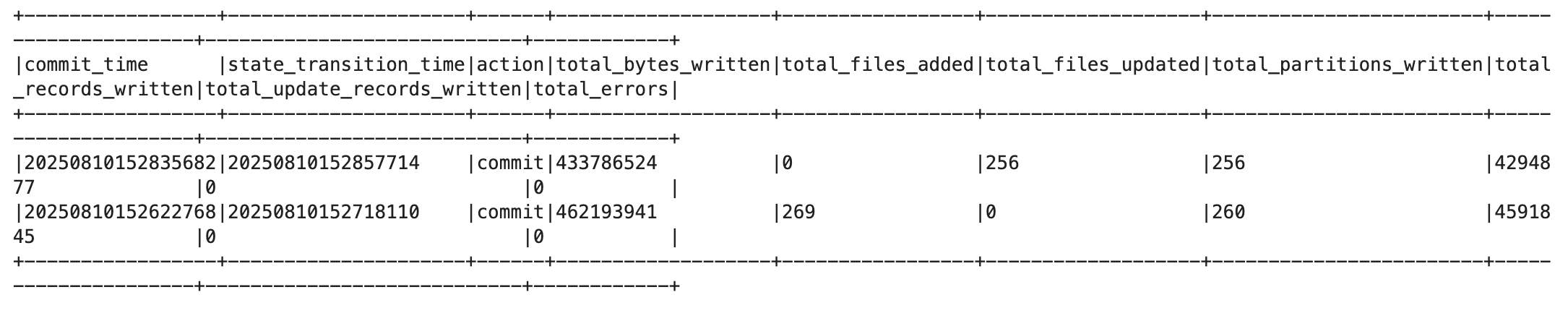
Each commit gets a timestamp ID like 20250810152622768. That’s how time travel works in Hudi - no version numbers or snapshot IDs like in Iceberg or Delta.
If you want to query a past state, you use the commit timestamp:
df = spark.read.format("hudi") \
.option("as.of.instant", "20250810152622768") \
.load("s3a://my-bucket/hudi-lakehouse/nyc/taxis/")It works, but it feels more manual. You need to manage those timestamps carefully, there’s no built-in "show me what versions exist" unless you call special Hudi procedures.
Schema evolution in Hudi works in two ways. You can add columns through SQL:
ALTER TABLE nyc.taxis_hudi ADD COLUMNS (fare_bucket STRING)But Hudi also supports writer-side schema evolution - you can add columns on the fly when writing data. When I added the tip_rate_pct column, I just included it in my DataFrame and Hudi automatically evolved the schema:
df_with_new = df.withColumn("tip_rate_pct",
round(col("tip_amount") / col("total_amount") * 100, 2))
# Write with schema evolution enabled
df_with_new.write.format("hudi") \
.option("hoodie.schema.on.write.enable", "true") \
.option("hoodie.datasource.write.reconcile.schema", "true") \
.mode("append").save(path)That worked surprisingly well, though I found out that dropping columns through SQL isn’t supported in my setup. Partition evolution also isn’t supported. Whatever partitioning you choose at the start - that’s it. You want something new? Rebuild the table.
After running everything I looked at MinIO again. The .hoodie folder was packed with logs and metadata. The partition folders were full of UUID-named files, many of which were duplicated or rewritten across commits. The structure was dense and harder to navigate than Iceberg or Delta. It works, but it’s noisy.
If you’re brave enough to try it yourself, the notebook is here: hudi.ipynb
The Ugly Truth About All Three
After spending way too much time staring at MinIO buckets, here's what I learned:
The Good Stuff
- Time travel works exactly as advertised. Rolling back feels almost unfairly easy.
- Schema evolution is straightforward in all three.
- Iceberg’s partition evolution is the only one that lets you change your strategy without rebuilding the whole table. That’s genuinely useful.
The Annoying Stuff:
- Spark errors are still garbage. "Task failed successfully" type of garbage
- The amount of small files these formats create is insane (hello, S3 request costs). Apparently, all of them have compaction and optimization mechanisms, but you have to trigger them yourself.
- Hudi's setup makes you question your life choices
The Surprising Stuff:
- How different they are under the hood despite doing similar things
- You can learn a lot just by watching files pile up - old ones, new ones, rewritten ones - and realizing nothing truly gets deleted right away. The formats just stop pointing to them in metadata, leaving them orphaned until a cleanup runs.
There’s no magic here. Just some smart ways of arranging files and metadata so object storage can act like a database. Once you see how it works, it’s less mysterious and a lot easier to reason about.
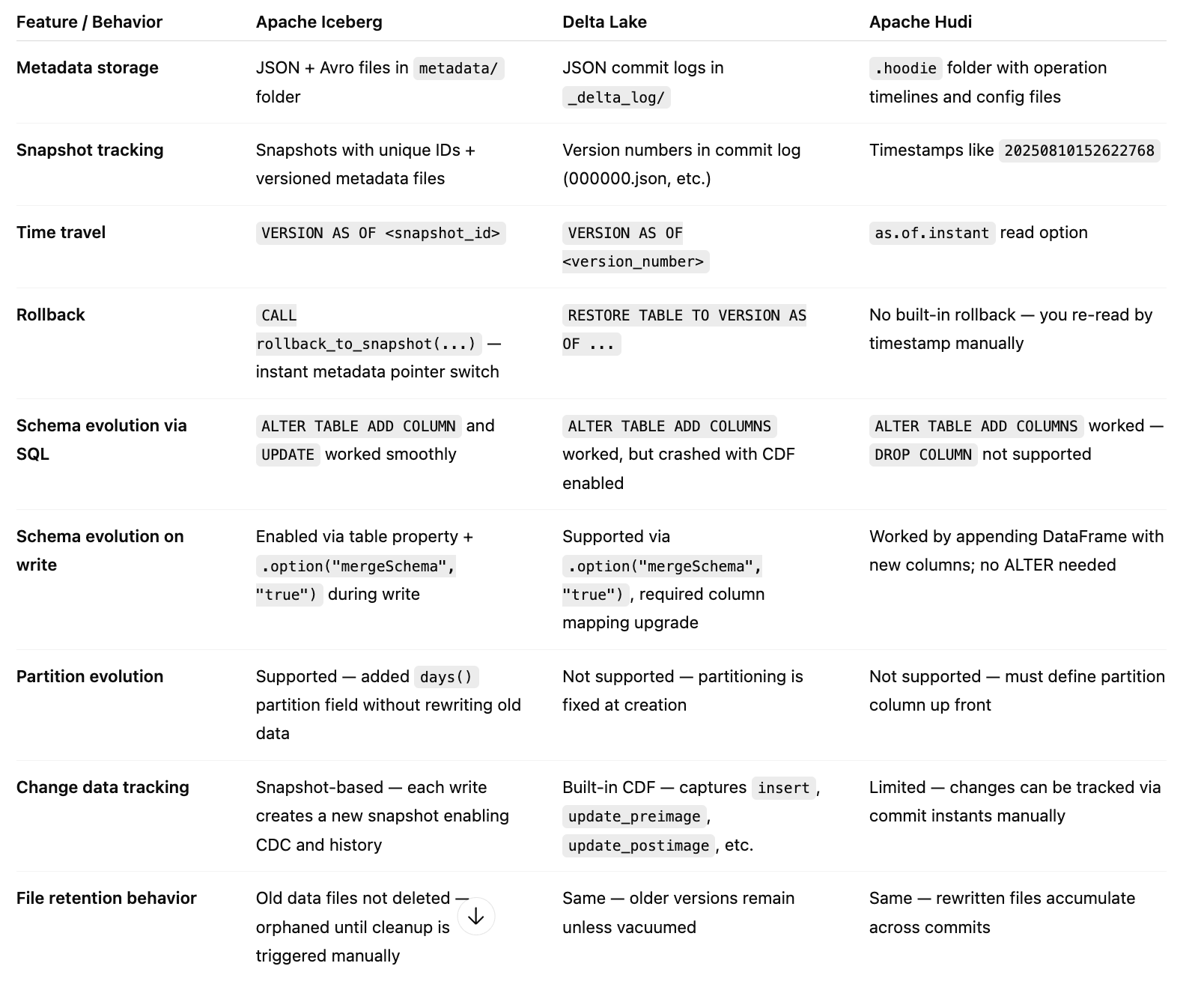
Here’s a quick comparison of how the three formats behaved in practice:
Try It Yourself (Seriously, It's All on GitHub)
I put everything on GitHub - the docker-compose file, the notebooks, even my janky scripts for watching the MinIO bucket. Clone it, run docker-compose up and start breaking things.