Build in Public: Week 1
The first week wasn’t particularly shiny. We mostly tried to move from our old n8n setup to a normal backend and figure out what “normal” even means for us. Somewhere along the way we also had our first team conflict and our first real issue with Bright Data, so I guess that officially makes it a real project now.
Apparently People Read This
Before we get into the actual work, a quick surprise from week one.
The first post - Build in Public: Day Zero - somehow got way more attention than I expected. It even made it into Dev.to’s Top 7 of the Week, which still feels a bit unreal.
A few people also reached out on LinkedIn and Twitter saying they liked the idea and wanted to start their own build-in-public projects. Which is honestly the best possible outcome so if you’re reading this, consider it your reminder to go build something too.
Backend Wars, Episode I
We now have the first working backend. Or rather, two of them.
When two people with different backgrounds build one project, a tech conflict is pretty much guaranteed. I come from data engineering, so for me Python is the natural choice for an AI agent. Alex is a full-stack developer, so he went with Node.js. After a week of back and forth we still haven’t agreed on anything. At this point we’ll probably have to open a LinkedIn poll and let the internet decide. Someone here is too stubborn to believe in Python.
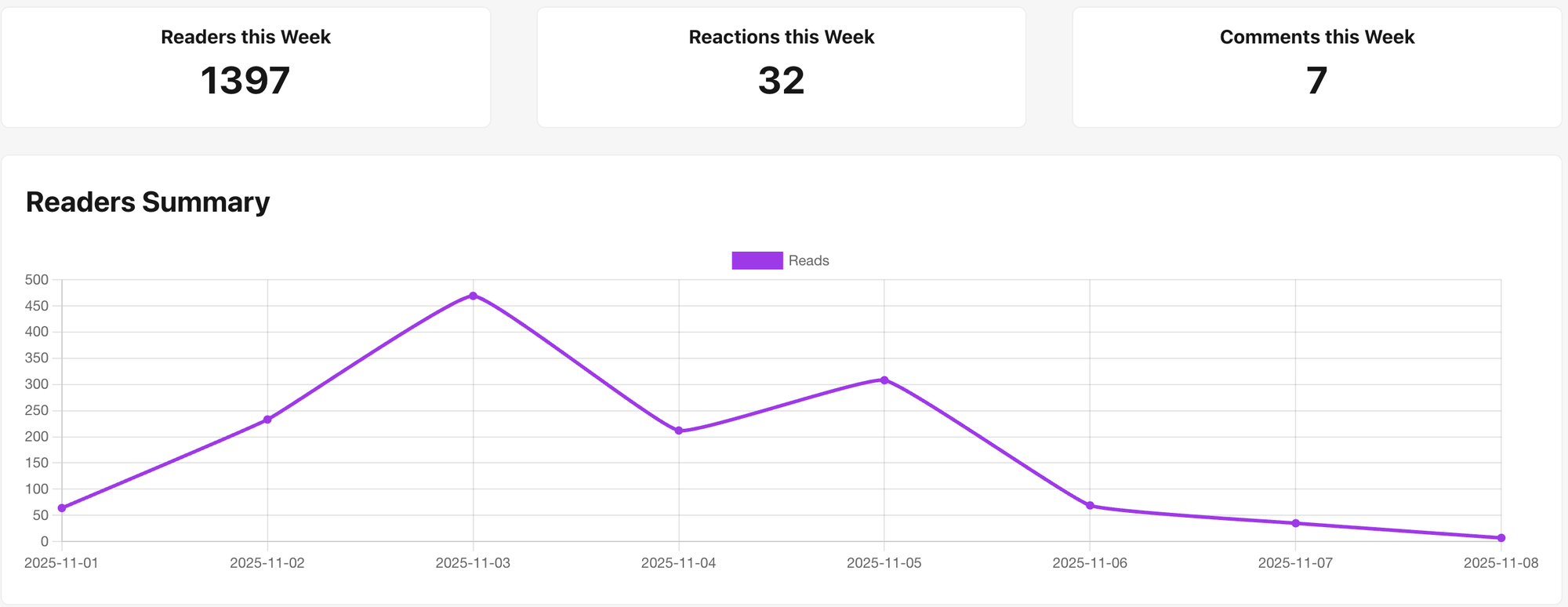
For now we’re focusing on Instagram and using Bright Data’s Instagram API scrapers. They offer two modes: synchronous (real-time) and asynchronous. I went with the async one; Alex’s version uses the real-time one. You can also test profiles manually from the UI - here’s an example with Taylor Swift’s profile.
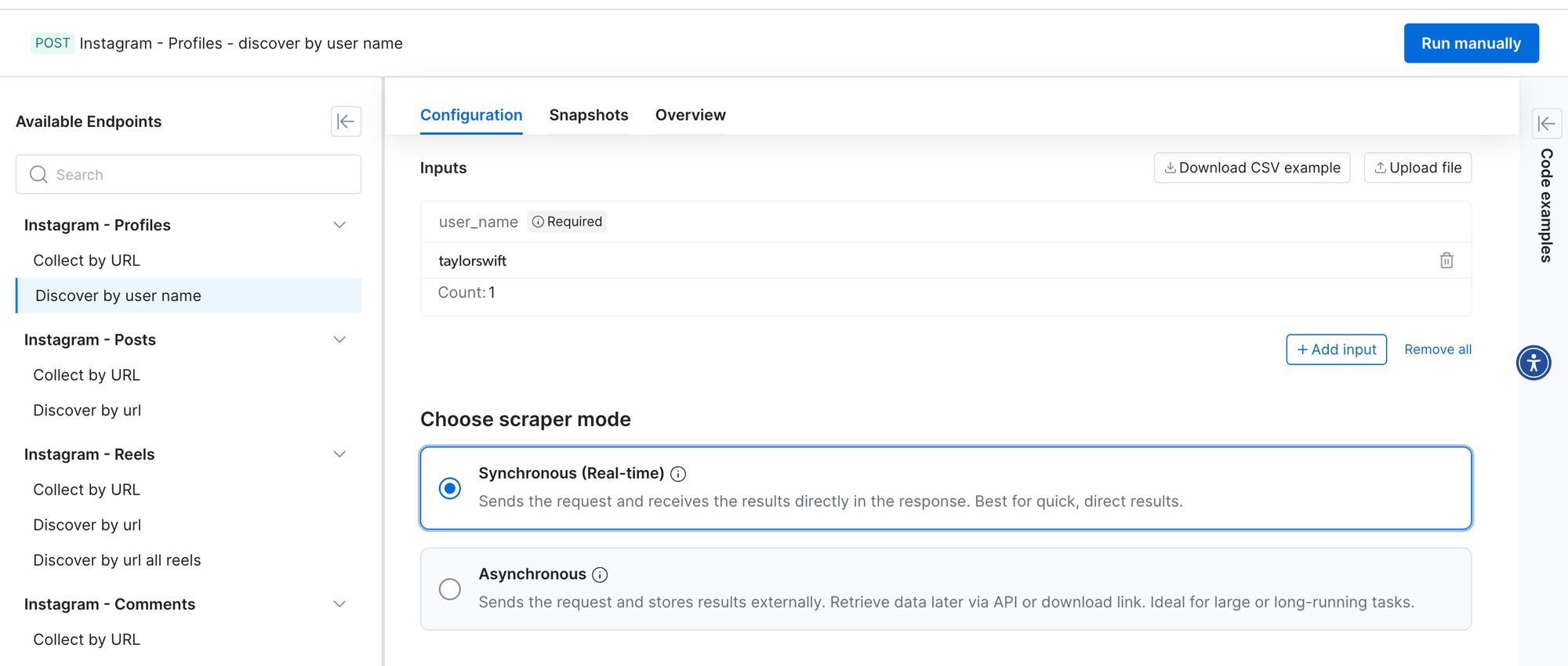
The response from Bright Data is a big JSON with everything you’d expect from a profile: username, full name, follower count, following, bio, profile image and whether it’s a business account. It also includes engagement rate, related accounts, and a list of recent posts with captions, likes and links to the media. Each post has a timestamp, so you can see how active the account is.
Once we get the profile JSON, we send it to the model for analysis. For now we use OpenRouter (anthropic/claude-3.5-sonnet) because their limits are reasonable and switching models there is easy. In the Python version I run it through Pydantic AI with this prompt (in the Node.js version Alex uses LangChain for orchestration):
The response comes back as a clean JSON, which makes it easy to reuse later for filtering or scoring. It’s not the final version of the analysis logic yet, but it’s already useful enough to see who’s real, who’s trying too hard and who’s just there for the hashtags.
For example, what it returns for Taylor Swift's profile:
If you want to try it yourself, both backends are available as separate repositories. Each can be run with Docker or Docker Compose, so you don’t need to install anything manually. The README files in both repos include all the setup details and yes, I spent an unreasonable amount of time making them nice. Please look at them, they deserve it. And if you like the project, give the repo a ⭐, it keeps the motivation alive.
- Python version: https://github.com/wykra-io/wykra-api-python
- Node.js version: https://github.com/wykra-io/wykra-api
Real-Time, Real Life
Yesterday evening, right when everything was finally working, Bright Data’s Instagram scraper started acting up. What used to take a few seconds suddenly stretched to 15–25 minutes per profile.
I even opened the ticket straight from the same run that got stuck, the classic “it was working five minutes ago” moment.
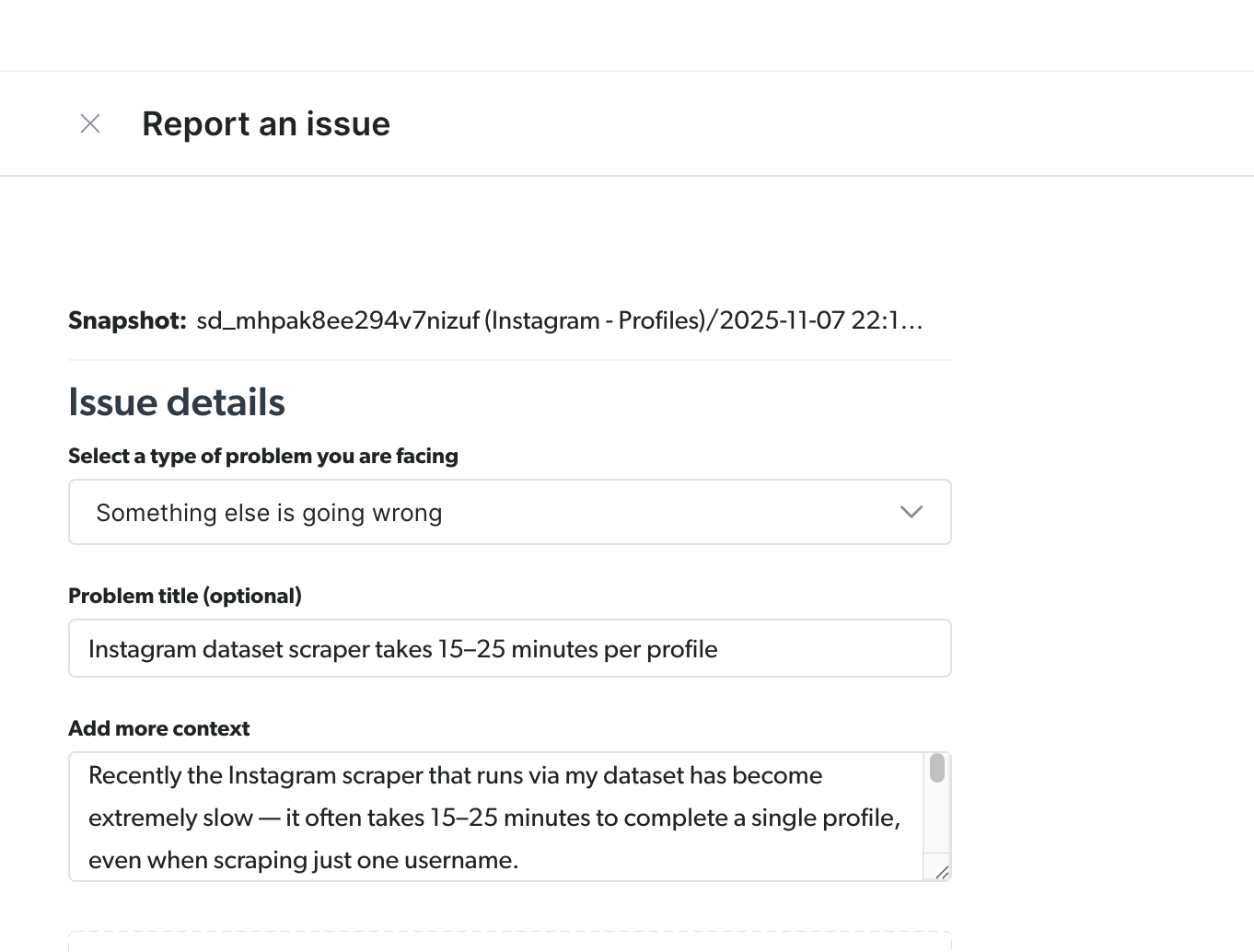
To their credit, the support team replied almost immediately, which honestly deserves respect.

The issue is still there and of course it happened exactly when I sat down to record the demo. I was planning to show a smooth “run → analyze → result” flow, but instead got a timeout at five minutes and later a 500 error.
It’s fine. This is just how real projects work. Even great tools have their off days, and when you build something that depends on live APIs, things like this are part of the deal.
The demo will have to wait until the scraper is back to normal. Real-time sometimes just means “not this week.”
Let’s Talk About Money
If we’re already talking about what it’s really like to build something, let’s talk about money.
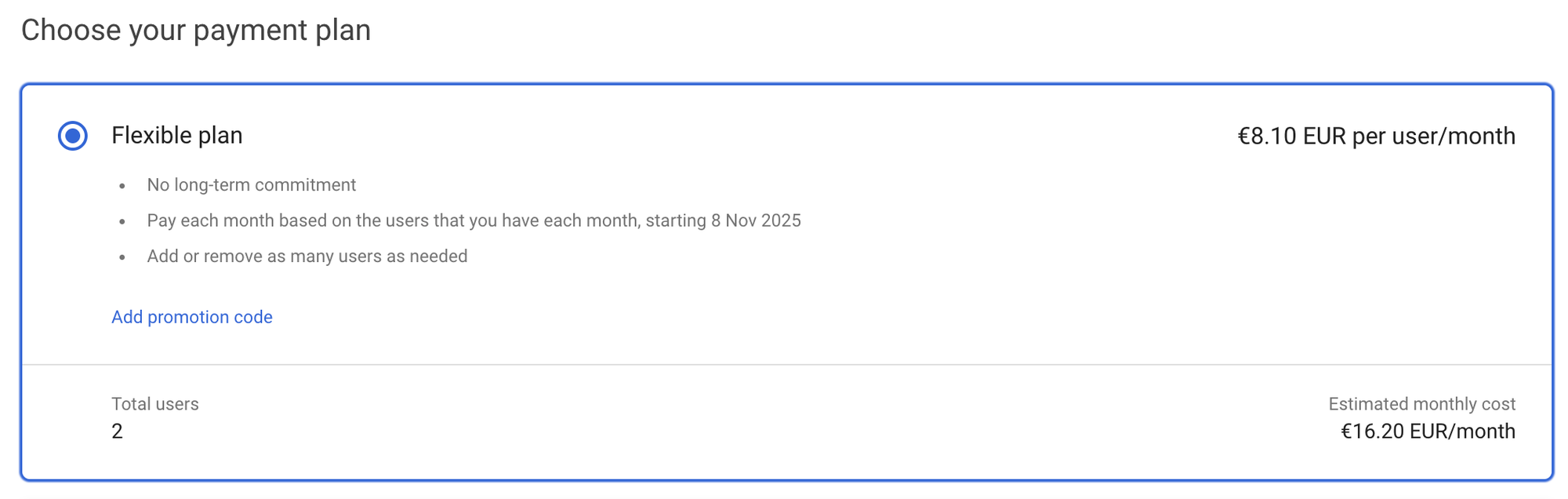
This week I set up Google Workspace for Wykra and somehow it decided that I clearly run a multinational corporation. It didn’t even offer the basic plan it jumped straight to Business Plus, €25.30 per month. I didn’t realize that was the per-user price; I thought it was for the whole workspace. Then I added a second user and now the billing page proudly shows “x2.”
So the actual bill is €50.60 a month. For what? For email. I later found out that I could actually downgrade and switched to Google Workspace Business Starter, which instantly made a lot more sense. Still even that isn’t exactly cheap for two email accounts and it was a good reminder to always check what exactly you’re paying for.
Then there are the other tools. Bright Data works on credits, OpenRouter too, so I bought about $30 worth to get things running and do some initial testing.
At least GitHub was kind enough to let me create a free organization, the only part of this setup not trying to charge me monthly.
None of this is dramatic, but it’s a good reminder that once you start building something for real, you also have to become your own finance department.
Next week, hopefully: a faster scraper, one demo video and maybe a winner in the Great Backend War. Also on the list - some actual research. I’m planning to look at what existing tools do, talk to a marketer who works with influencer discovery and figure out what kind of analysis people actually need and how they find creators in practice. With any luck, that will give us a clearer direction for what to build next.
Repo: https://github.com/wykra-io/wykra-api and https://github.com/wykra-io/wykra-api-python
Follow me on Twitter: https://x.com/ohthatdatagirl